Tämä dokumentti kuvaa EdgeAI-projektin anomaliatunnistusratkaisun (poikkeamien tunnistus) toteutuksen ja ML-prosessin.
Ratkaisu tunnistaa poikkeavat mittauspisteet servon liikeradan sensoridatasta käyttäen IsolationForest-mallia (scikit-learn),
ja se on suunniteltu toimimaan ilman erillistä poikkeamalabelointia (unsupervised).
1.1 Tavoitteet
Tunnistaa poikkeamat reaaliaikaisesti sensoridatasta
Minimoida virheellisten hälytysten määrä
Toimia luotettavasti eri olosuhteissa
1.2 Määritelmät
Anomalia (poikkeama): datapiste, joka poikkeaa mallin oppimasta normaalista käyttäytymisestä (mallin predict palauttaa -1).
Anomaly score: mallin decision_function-arvo. Tässä toteutuksessa matalampi score = epänormaalimpi.
Ajokerta (run): yksi JSON-tiedosto, joka sisältää yhden mittausajon (measurements-lista).
1.3 Teknologiapino
Python 3.12+
scikit-learn (Isolation Forest)
pandas (datan käsittely)
numpy (numeeriset operaatiot)
matplotlib/seaborn (visualisointi)
joblib (mallin tallennus)
Projektin toteutuksen lähde
Tämän dokumentin tekniset yksityiskohdat vastaavat ML-kansion toteutusta:
ML/anomalydetect.ipynb
ML/generate_graphs.py
ML/feature_order.json
ML/anomaly_model.pkl ja ML/feature_scaler.pkl
2. ML-putken arkkitehtuuri
Ratkaisu noudattaa selkeää ML-putkea (data → feature engineering → skaalain → malli → scoring/päätös). Lisäksi tuotetaan dokumentointia tukevat kuvat valmiiksi.
Sensoridata kerätään Servon liikeradan mittaus -laitteelta ja tallennetaan JSON-muotoon.
Jokainen tiedosto sisältää yhden mittausajon. Tässä dataa on kerätty yhdeksän
mittausjakson ajalta (9 ajokertaa). Kussakin ajokerrassa on tyypillisesti 54 mittausta (yhteensä 486 datapistettä).
Huomio datamäärästä
Nykyinen datasetti on pieni. Tämä on riittävä prototypointiin ja end-to-end -putken todentamiseen, mutta tuotantokäyttöön suositellaan lisää dataa
eri olosuhteista (kuorma, lämpötila, mekaaninen kuluma, kiinnitykset) sekä mielellään myös poikkeamien manuaalista validointia.
Raakadatasta luodaan seuraavat featuret. Feature-järjestys on kriittinen ja vastaa tiedostoa ML/feature_order.json.
Feature
Kuvaus
Tarkoitus
angle
Kulma (asteina)
Laitteen asento
acc_x, acc_y, acc_z
Kiihtyvyys akselittain
3D-liikkeen analyysi
acc_total
Kokonaiskiihtyvyys
Yleinen liike
d_angle
Kulman derivaatta
Äkilliset käännökset
d_acc_total
Kiihtyvyyden derivaatta
Äkilliset kiihtyvyyden muutokset
acc_total_ma
Liukuva keskiarvo (5)
Trendien tasoitus
acc_total_std
Liukuva std (5)
Värinän tunnistus
3.3 Train/test-jako (ajokertataso)
Train/test-jako tehdään ajokertojen perusteella, jotta testijoukossa on kokonaisia mittausajoja, joita ei ole nähty koulutuksessa.
Tämä on tärkeää erityisesti aikasarjamuotoisessa datassa ja vähentää data leakagen riskiä.
Kaikki featuret skaalataan StandardScaler-muunnoksella. Skaalain fitataan vain train-dataan ja samaa muunnosta käytetään testiin ja tuotantoon.
Datan laatu
Varmista että:
Datan aikaleimat ovat johdonmukaisia
Ei ole puuttuvia arvoja
Kaikki mittausajot ovat samanpituisia
Sensorien yksiköt ja mittausskaalat pysyvät vakioina (muuten score-jakauma driftää)
4. Mallinnus ja koulutus
4.1 Isolation Forest
Isolation Forest on tehokas anomaliatunnistusalgoritmi, joka:
Toimii ilman labeleita (unsupervised)
On nopea ja skaalautuva
Sopii hyvin moniulotteiselle datalle
4.2 Mitä malli tuottaa
Luokitus: predict(X) antaa 1 (normaali) tai -1 (anomalia).
Pistemäärä: decision_function(X) antaa jatkuvan score-arvon, jota käytetään analyysiin ja kynnysarvoihin.
4.2 Parametrit
iso_forest = IsolationForest(
n_estimators=100, # Puiden määrä
contamination=0.05, # Oletus poikkeamien osuudeksi
random_state=42, # Reproducibility
n_jobs=-1 # Rinnakkaisuus
)
4.3 Train/Test-jako
Data jaetaan ajokertojen perusteella:
Train (80%): 7 ajokertaa
Test (20%): 2 ajokertaa
Scaler fitataan VAIN train-dataan ja käytetään samaa skaalaineria test-datalle. Tämä estää data leakagen.
4.4 Reproducibility ja determinismi
Satunnaisuus: random_state=42 tekee koulutuksesta toistettavamman.
Artefaktit: malli, skaalain ja feature-järjestys tallennetaan ja niitä käytetään sellaisenaan tuotannossa.
5. Evaluointi
5.1 Metriikat
Train Data
5.0%
Poikkeamien osuus
Test Data
1.9%
Poikkeamien osuus
Yleistymiskyky
3.1%
Ero prosenttiyksikköinä
Mitä nämä luvut tarkoittavat tässä ratkaisussa?
Tässä projektissa käytössä on IsolationForest ilman ground truth -labeleita. Tällöin “metriikat” ovat ensisijaisesti
käyttökelpoisuus- ja stabiilisuusmittareita (eivät lopullisia laatumittareita kuten precision/recall).
Train Data 5.0%: Mallin contamination=0.05 ohjaa päätösrajaa niin, että train-datasta noin 5% pisteistä luokitellaan poikkeamiksi.
Tämä on odotettu tulos, eli se kertoo ennen kaikkea että malli toimii teknisesti oikein.
Test Data 1.9%: Poikkeamien osuus uudessa datassa samalla mallilla ja samalla skaalauksella.
Jos test-datan “normaali käyttäytyminen” on sama kuin trainissa, osuuksien tulisi yleensä olla melko lähellä toisiaan.
Yleistymiskyky 3.1%-yks.: Erotus train vs test -anomaliaosuudessa.
Tämä on nopea signaali siitä, onko data- tai prosessimuutoksia (drift) tai onko datasetti pieni/epästabiili.
Tärkeä huomio: “Vähemmän poikkeamia testissä” ei automaattisesti tarkoita parempaa mallia.
Se voi tarkoittaa myös sitä, että testiajot ovat erilaisia (tai datasetti on pieni), jolloin päätösrajan tulkinta muuttuu.
Evaluointi ilman ground truth -labeleita
Koska kyseessä on unsupervised-anomaliatunnistus, perinteiset luokittelumetriikat (precision/recall) eivät ole käytettävissä ilman labelointia.
Tämän vuoksi evaluointi keskittyy:
Stabiiliuteen: score-jakaumien ja poikkeamaprosentin vertailu train vs test.
Järkevyyteen: poikkeamien sijoittuminen ajassa ja ajokerroissa.
Kun tuotannossa halutaan mitata “todellista laatua”, tarvitaan vähintään:
(1) poikkeamien manuaalinen validointi otokselle tai
(2) heuristiikka/konfiguroitu sääntö, joka määrittelee mitkä tapahtumat ovat oikeita vikoja.
5.2 Visualisointi
Järjestelmä tuottaa seuraavat visualisoinnit:
Anomaly score jakauma (train vs test)
Poikkeamien sijoittuminen aikajanalla
Featurejen korrelaatiot
2D-projektio poikkeamista
Miksi visualisointeja tarvitaan?
Unsupervised-anomaliatunnistuksessa visualisoinnit ovat käytännössä tärkein tapa varmistaa, että malli tekee järkeviä päätöksiä:
nähdään miten score käyttäytyy, milloin poikkeamat syntyvät ja minkä tyyppisiin signaalimuutoksiin malli reagoi.
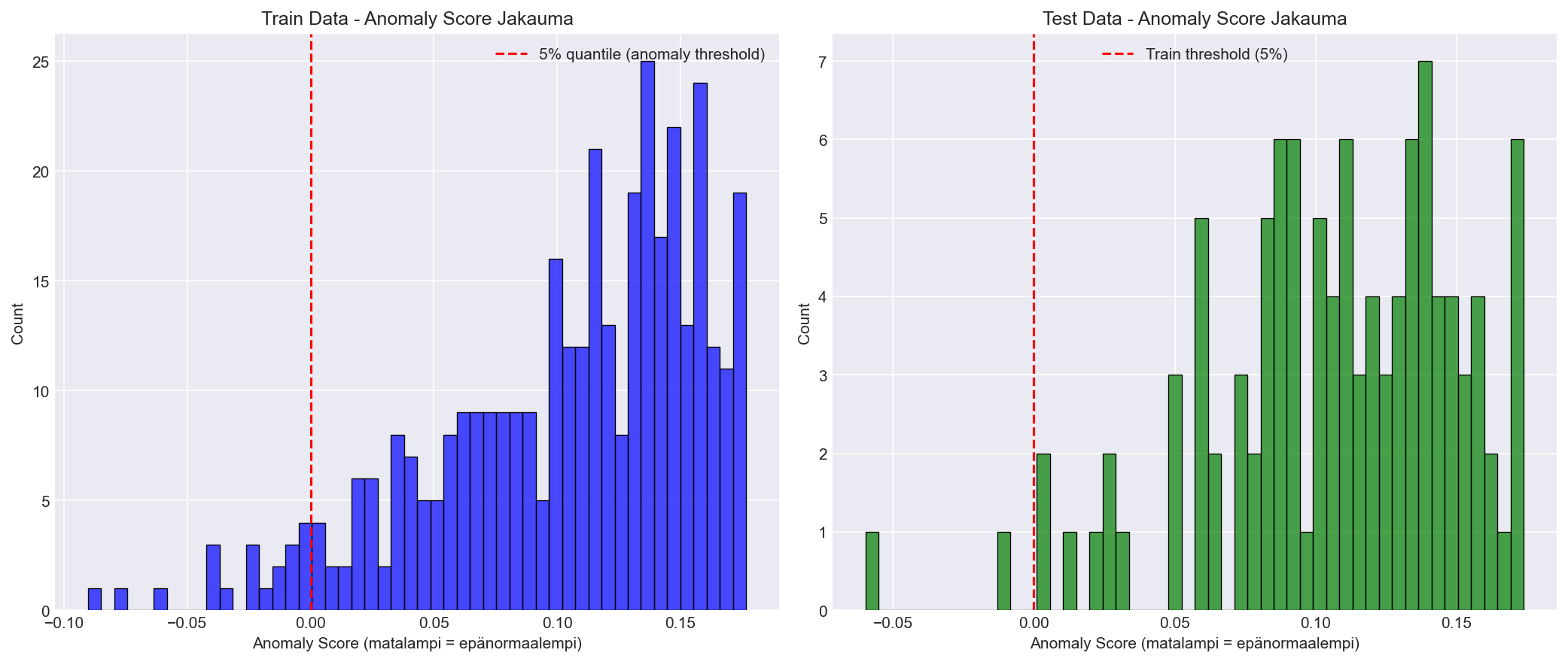
5.2.1 Anomaly Score Jakauma
Train ja test -datojen anomaly score jakaumat näyttävät, kuinka malli pisteyttää eri datapisteitä:
Miten tulkita:
Score-akselilla matalampi arvo tarkoittaa “epänormaalimpaa”.
Punainen katkoviiva (train 5% kvantiili) on suuntaa-antava raja: pisteet sen vasemmalla puolella ovat “anomalisempia”.
Jos testin jakauma siirtyy selvästi verrattuna trainiin, kyse voi olla driftistä (sensorin offset, kuorma, asennus, ym.).
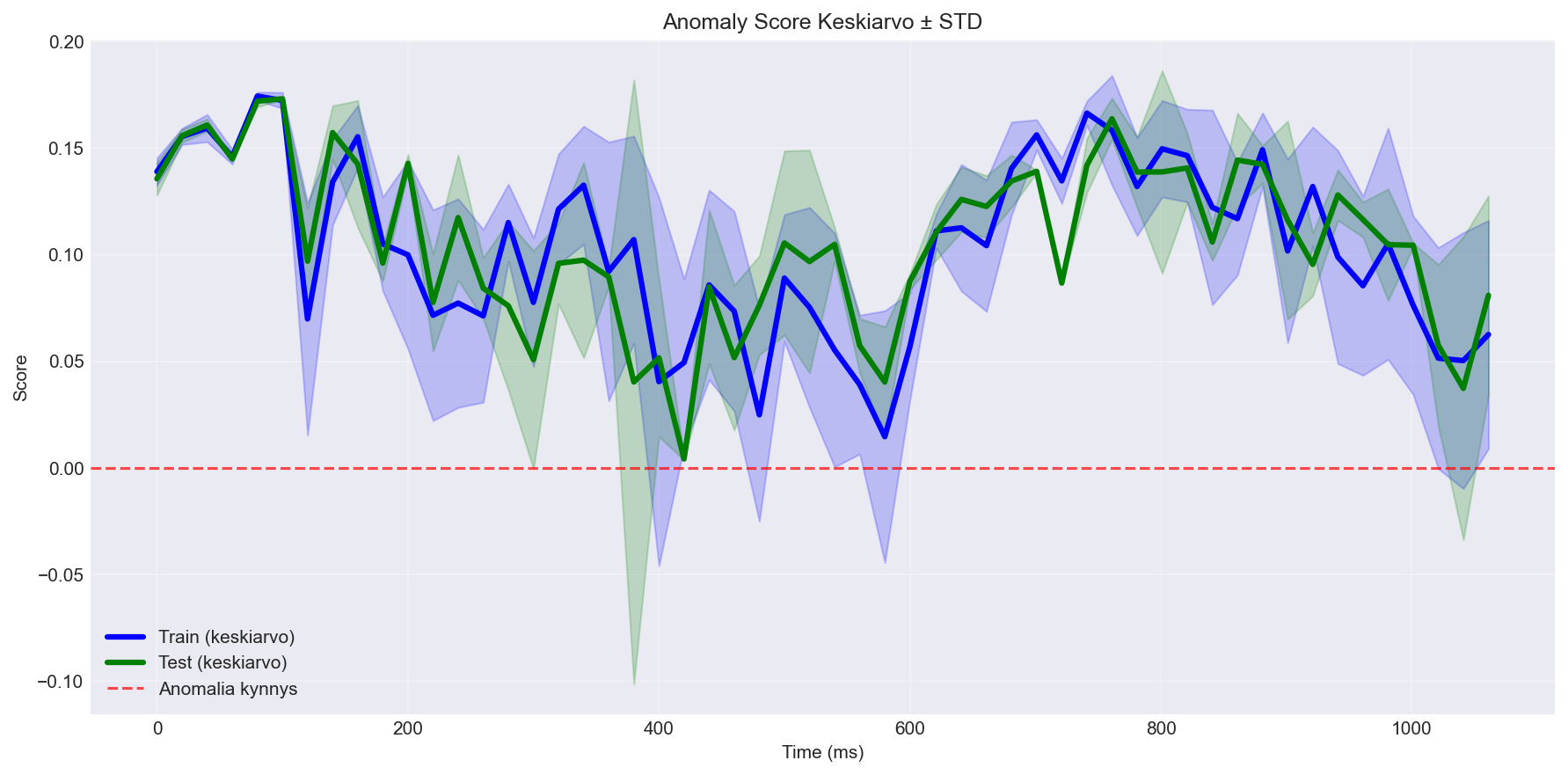
5.2.2 Anomaly Score ajan funktiona
Keskiarvoistettu anomaly score ajansuhteen näyttää systemaattiset muutokset mittauksen aikana:
Miten tulkita:
Kuva esittää score-keskiarvon sekä vaihteluvälin (± std) ajan suhteen.
Jos tietyissä time_ms-kohdissa score tippuu systemaattisesti, malli näkee liikeradan siinä vaiheessa epänormaalina.
Tämä auttaa erottamaan “satunnaiset yksittäispisteet” vs. “systemaattinen poikkeama liikkeen tietyssä vaiheessa”.
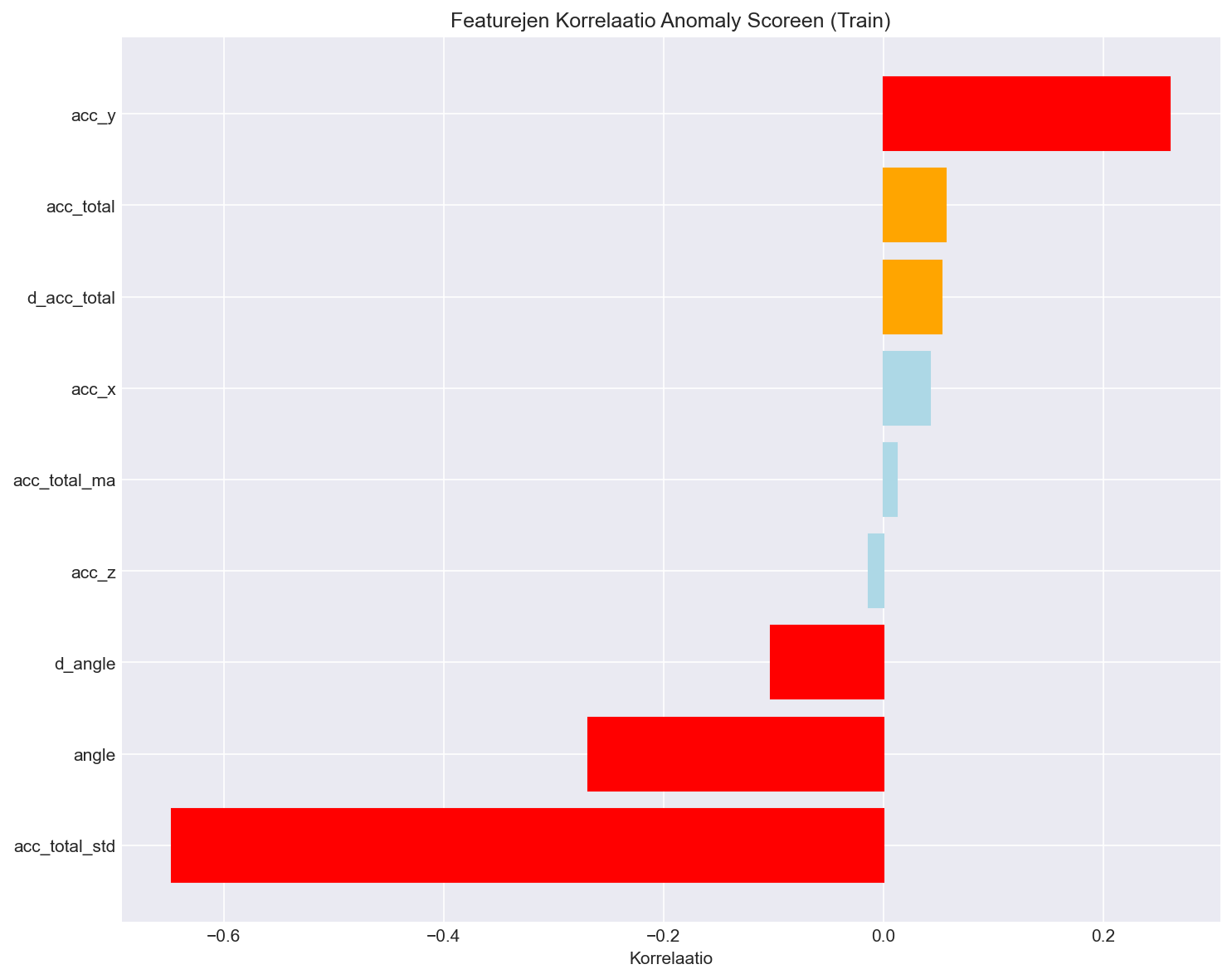
5.2.3 Featurejen Korrelaatiot
Featurejen korrelaatiot anomaly scoreen näyttävät mitkä ominaisuudet vaikuttavat eniten poikkeamien tunnistukseen:
Miten tulkita:
Tämä on suuntaa-antava analytiikka: korrelaatio ei ole kausaliteetti.
Suuret itseisarvot kertovat, että kyseinen feature muuttuu usein samanaikaisesti score-muutosten kanssa.
Käytännössä tämä auttaa priorisoimaan mitä signaaleja tarkastellaan, kun poikkeamia tutkitaan (esim. acc_total_std liittyy värinään).
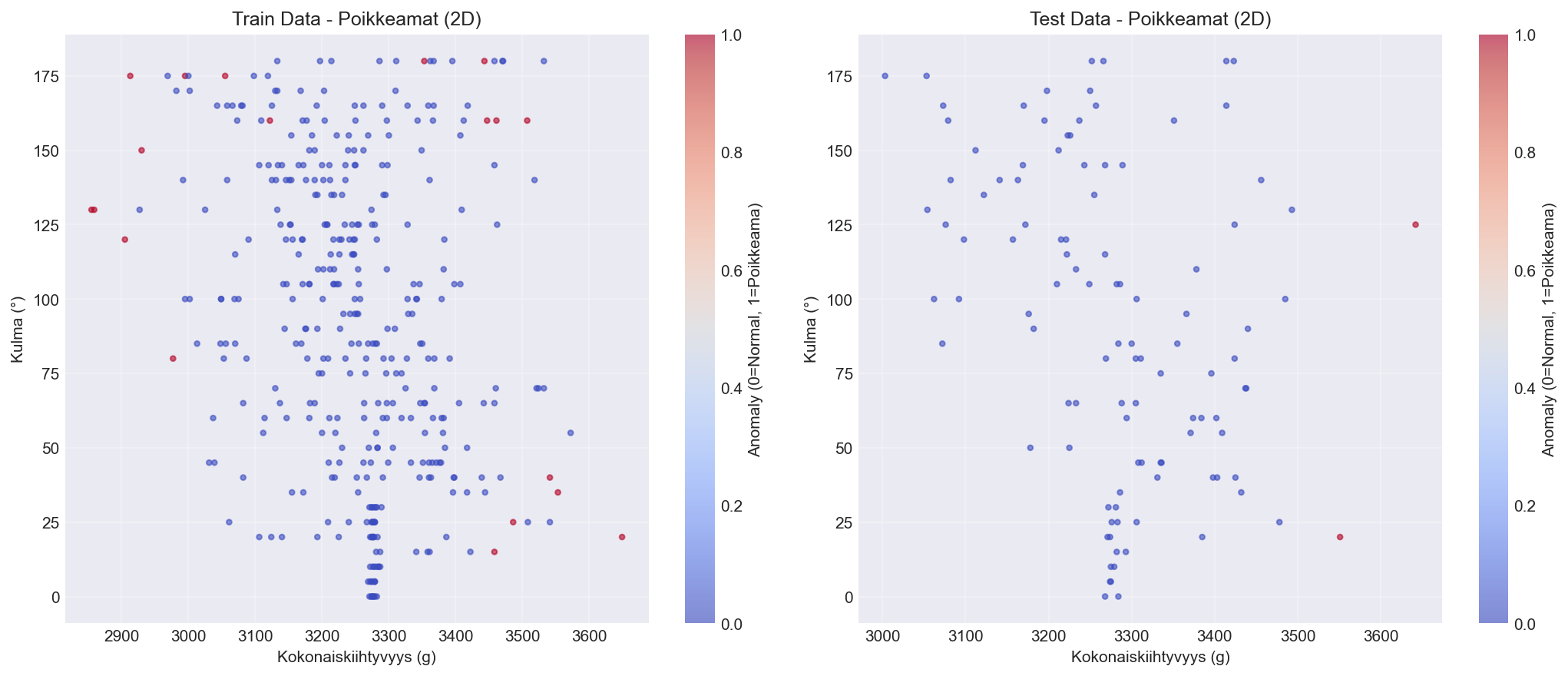
5.2.4 Poikkeamat 2D-projektiossa
2D-projektio kulman ja kokonaiskiihtyvyyden avulla visualisoi poikkeamien sijoittumista:
Miten tulkita:
Jos poikkeamat keskittyvät tiettyyn kulma-alueeseen, se voi viitata mekaaniseen ongelmaan tietyssä liikeradan osassa.
Jos poikkeamat ovat hajallaan ilman rakennetta, kyse voi olla herkkyydestä kohinalle tai featuret eivät erottele ilmiötä selkeästi.
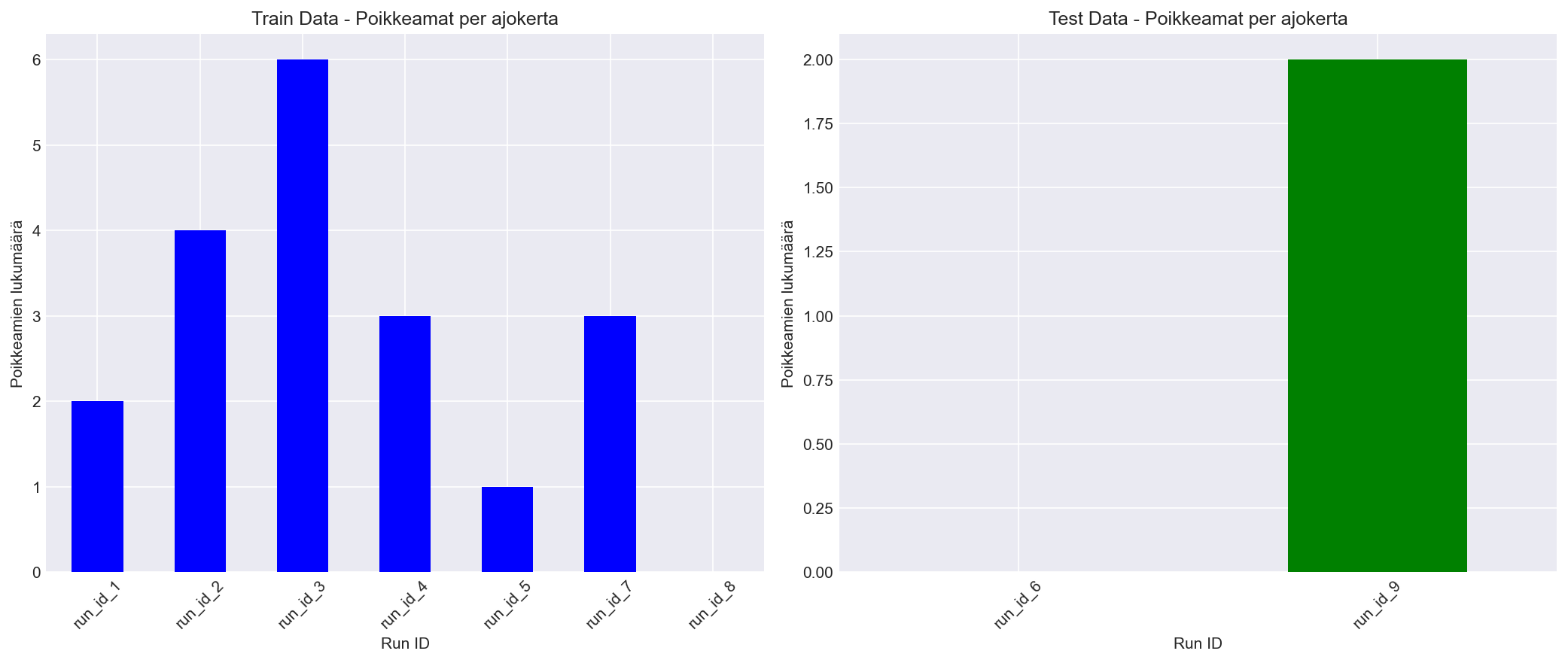
5.2.5 Poikkeamien Määrä per Ajokerta
Poikkeamien määrä eri ajokerrissa näyttää vaihtelua mittausajojen välillä:
Miten tulkita:
Jos yksi ajokerta tuottaa selvästi muita enemmän poikkeamia, se kannattaa tarkistaa ensin (data, sensorit, olosuhteet).
Jos train-ajokerroissa on paljon vaihtelua, myös contamination- ja hälytyslogiikan säätö voi olla tarpeen.
5.3 Tulosten tulkinta
Hyvä yleistymiskyky: Ero < 2%
Kohtalainen: Ero 2-5%
Heikko: Ero > 5%
Mitä voit päätellä näistä tuloksista (ja mitä et)
Voit päätellä: Onko score-käyttäytyminen stabiilia, löytyykö poikkeamia tietyistä liikkeen vaiheista, ja onko datassa ajokertakohtaista vaihtelua.
Et voi päätellä: Todellista “vikatunnistuksen tarkkuutta” ilman labelointia tai muuta totuusdataa.
Käytännön tulkinta ja suositus
Jos testissä poikkeamia on selvästi vähemmän: tarkista onko testiajot olosuhteiltaan erilaisia (kuorma, asento, kiinnitys, sensorin nollataso).
Pieni datasetti voi myös aiheuttaa isoja heilahteluja.
Jos testissä poikkeamia on selvästi enemmän: tämä on usein vahvempi signaali driftistä tai uudesta ilmiöstä (esim. värinä lisääntynyt).
Jos poikkeamat kasautuvat tiettyyn time_ms-kohtaan: viittaa liikeradan tiettyyn vaiheeseen liittyvään ongelmaan (mekaniikka / resonanssi / rajoitin).
Hälytyksen muodostaminen (suositus)
Yksittäinen poikkeamapiste ei yleensä ole riittävä hälytysperuste. Tyypillisesti parempi on:
Aggregointi: hälytä jos esim. viimeisen N pisteen (tai yhden ajokerran) poikkeamaosuus ylittää rajan.
Score-pohjainen kynnys: seuraa score-kvantiileja (esim. 1% tai 5%) ja reagoi vasta, kun ne siirtyvät pysyvästi.
Kalibrointi: kerää tuotannosta baseline ja säädä contamination/hälytysraja vastaamaan hyväksyttävää false alarm -tasoa.
Nykyisen datan tulkinta
Testissä havaitaan vähemmän poikkeamia kuin trainissa, ja notebook-analyysissä poikkeamien ominaisuudet eroavat train vs test.
Tämä voi johtua mm. pienestä otoksesta, ajokertojen välisestä vaihtelusta, mittausasetelman muutoksista tai todellisesta driftistä.
def detect_anomalies(new_data):
# Lataa mallit
model = joblib.load('anomaly_model.pkl')
scaler = joblib.load('feature_scaler.pkl')
feature_order = json.load(open('feature_order.json', 'r'))
# Valmistele data
X = new_data[feature_order].values
X_scaled = scaler.transform(X)
# Tee ennuste
predictions = model.predict(X_scaled)
scores = model.decision_function(X_scaled)
return predictions, scores
6.3 Kynnysarvot ja hälytyssäännöt
Tässä toteutuksessa contamination=0.05 ohjaa mallin sisäistä päätösrajaa siten, että train-datassa noin 5% pisteistä merkitään poikkeamiksi.
Dokumentointigraafeissa visualisoidaan lisäksi train-scoren 5% kvantiili (np.percentile(train_scores, 5)) suuntaa-antavana kynnysviivana.
Tuotantohälytyksessä suositellaan käyttämään ajallista aggregointia (esim. N viimeisen mittauspisteen poikkeamaprosentti) yksittäisten pisteiden sijaan,
jotta virheelliset hälytykset vähenevät.
Tärkeää tuotannossa
Käytä aina samaa feature-järjestystä
Skaalaa data tallennetulla skaalainerilla
Tallenna tulokset ja seuraa suorituskykyä
Älä fit-taa skaalaineria tuotantodataan (muuten score-jakauma muuttuu ja driftin havainnointi vaikeutuu)
7. Monitorointi ja drift
7.1 Mitä monitoroidaan
Anomaly rate: poikkeamien osuus per ajokerta / per aikajakso.
Score-jakauma: decision_function-arvojen histogrammi ja kvantiilit.
Input-feature-jakaumat: erityisesti acc_total ja acc_total_std.
Poikkeamien kasautuminen: poikkeamat lisääntyvät tietyissä ajoissa tai tietyssä vaiheessa ajoa.
Feature-shift: featurejen jakaumat muuttuvat verrattuna koulutusdataan.
Suositus
Kerää tuotannosta score- ja feature-telemetriaa vähintään aggregaattitasolla (esim. kvantiilit per ajokerta) ja vertaa niitä koulutusdatan baselineen.
Tämä tukee sekä driftin havaintoa että hälytyskynnyksen säätöä.
8. Vianhaku
8.1 Yleiset ongelmat
Ongelma: KeyError puuttuvalle featurelle
Syy: Uusi data ei sisällä kaikkia tarvittavia featureja.
Ratkaisu: Varmista että kaikki featuret on laskettu samalla tavalla kuin koulutusdatassa.
Ongelma: Liian monta poikkeamaa
Syy: Contamination-parametri on liian suuri tai data on erilaista.
Ratkaisu: Säädä contamination-arvoa tai kerää lisää koulutusdataa.
Ongelma: Poikkeamat tulevat vain tietyissä ajokerroissa
Syy: Ajokertakohtainen vaihtelu (asennus, kuorma, sensorin offset) tai drift.
Ratkaisu: Vertaile feature-jakaumia train-baselineen ja harkitse ajokertakohtaista normalisointia tai uuden datan lisäämistä koulutukseen.
Ongelma: Malli ei lataudu
Syy: Mallitiedosto on korruptoitunut tai versio-ongelma.
Ratkaisu: Tarkista tiedostojen eheys ja scikit-learn versio.